Cuando exploramos datos pensamos en variables con números pero que sucede con la exploración de variables que no son numéricas (por ejemplo, sexo, usa o no usa internet, le gusta o no le gusta un alimento, etc). Son las llamadas variables categóricas.
Las dos categorías principales de datos categóricos son nominales y ordinales.
En el atributo de datos categóricos nominales, no existe el concepto de ordenar entre los valores de ese atributo.
Los atributos categóricos ordinales tienen algún sentido o noción de orden entre sus valores.
Los gráficos que se utilizan generalmente para visualizar este tipo de datos son
- grafico de barras
- grafico de conteo
- diagrama de caja
- enjambre
- diagrama de factores
Antes de continuar, importemos algunos datos de muestra con los que jugaremos. Usemos un conjunto de datos de muestra "Sugerencias" que brinde información sobre las facturas de un restaurante.
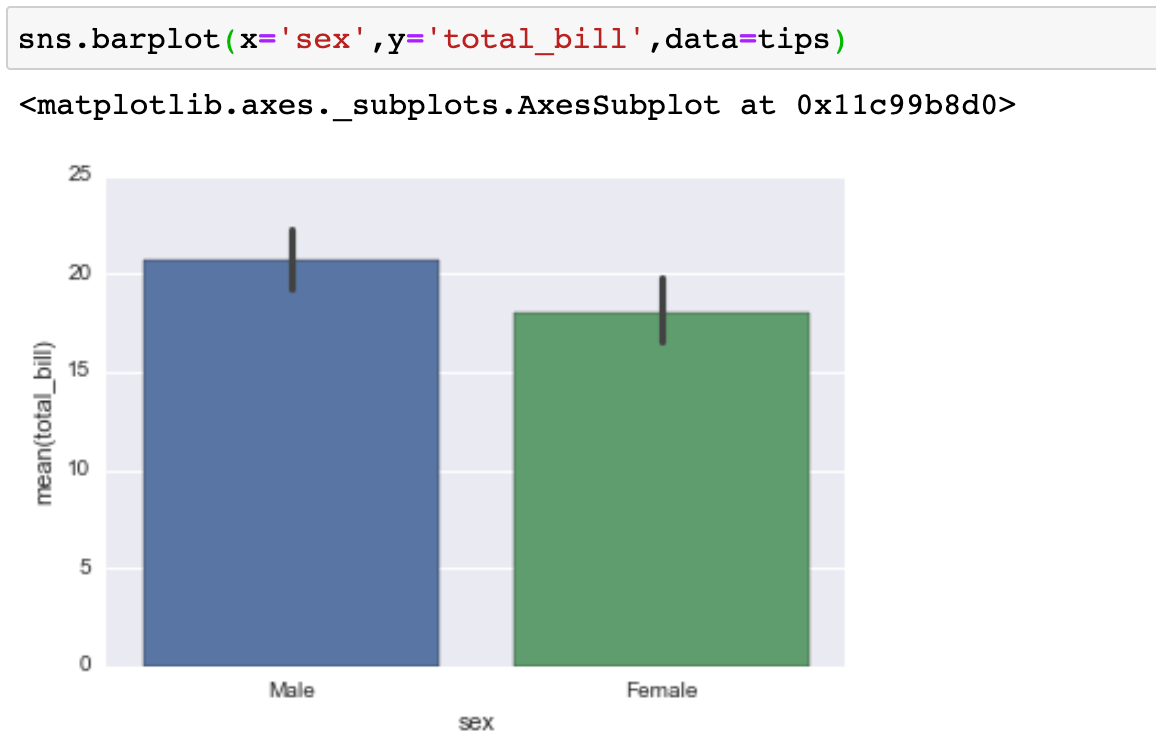
Grafico de Barras
Esta gráfica le permite obtener datos agregados de una característica categórica en sus datos. El ** barplot ** es un gráfico general que le permite agregar los datos categóricos basados en alguna función, por defecto la media:
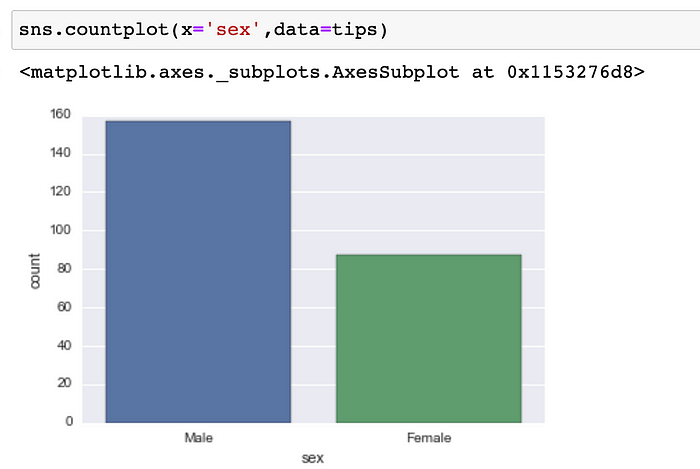
Grafico de conteo (Countplot):
Esto es esencialmente lo mismo que el diagrama de barras, excepto que el estimador está contando explícitamente el número de ocurrencias. Es por eso que solo pasamos el valor x:
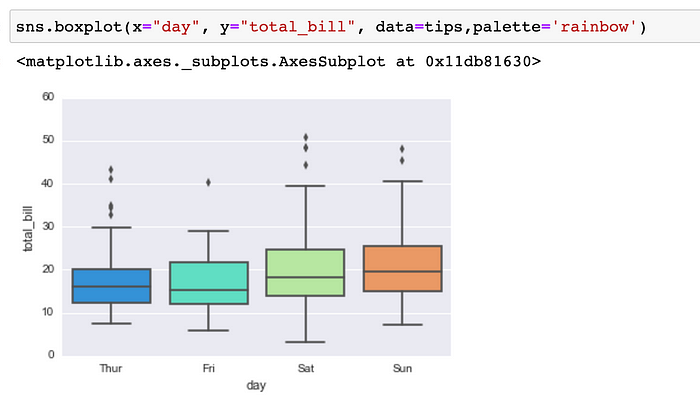
Diagrama de caja:
Un diagrama de caja es una forma estandarizada de mostrar la distribución de datos basada en un resumen de cinco números (“mínimo”, primer cuartil (Q1), mediana, tercer cuartil (Q3) y “máximo”).
Grafico de enjambres (Swarmplot):
Swarmplot: los puntos se ajustan (solo a lo largo del eje categórico) para que no se superpongan. Esto proporciona una mejor representación de la distribución de valores, aunque no escala tan bien a un gran número de observaciones (tanto en términos de la capacidad de mostrar todos los puntos como en términos del cálculo necesario para organizarlos).
Diagrama de factor:
factorplot es la forma más general de un diagrama categórico. Puede tomar un parámetro ** tipo ** para ajustar el tipo de gráfico: (variando el Kind en el cèdigo se puede cambiar de un tipo de grafico a otro)
COmo puede ver el grafico obtenido con factorplot es exactamente igual al obtenido con barplot, ya que kind = bar en el còdigo.
basado en: https://medium.com/@gauravdahiya/visualising-categorical-data-8fe887c98e57